デジタル時代において、情報はテキストや画像など、さまざまな形式で入手できます。コンピュータはテキストを簡単に処理できますが、画像から価値のあるデータを抽出することは、従来はより困難でした。しかし、人工知能の最近の進歩により、このプロセスが変化しました。OpenAIが開発した最先端の言語モデルであるChatGPTの機能は、画像からテキストを高精度で抽出できるという画期的なものです。この進歩により、視覚データとテキストデータのギャップを埋めるAIの力が示され、画像ベースの情報をよりアクセスしやすく、使いやすいものにしています。
ChatGPTの新しいビジョンモデルにより、ユーザーは光学文字認識(OCR)を実行できるようになり、画像やPDFからテキストを抽出できるようになりました。これらのモデルにより、スキャンした文書からのデータ抽出の自動化や、画像ベースのコンテンツをアクセスしやすく、編集可能なテキストに変換するなど、数多くの可能性が開かれています。
光学式文字認識(OCR)とは?
OCR(Optical Character Recognition)とは、手書き、活字体、印刷されたテキストを含む画像を、機械が読み取れるデジタルテキストに変換する自動処理です。OCRソフトウェアは、画像やスキャンされた文書からテキストを検出し、抽出して、編集可能なデジタルコンテンツに変換します。OCR技術は何十年も前から存在していますが、進化を続けており、精度とパフォーマンスが向上しています。高度なVisionモデルを搭載したChatGPTのOCR機能は、画像からテキストを読み取り、抽出する精度が最先端であり、テキスト認識の精度も高いレベルで保証されています。
OCRにおけるChatGPTの役割
ChatGPTのOCR機能は、Visionモデルを通じてアクセスでき、チャット中にユーザーがアップロードしたPNG、JPG、PDFファイルなどの形式の画像からテキストを認識し、抽出することができます。システムは画像をスキャンし、テキストを検出し、機械エンコードされた編集可能なデジタルコンテンツに変換します。この機能により、テキストを含むハードコピーの文書や画像をデジタル形式に変換し、編集や管理を容易にすることができます。さらに、ChatGPTのOCR機能は、グラフ、チャート、その他のテキスト要素を含む視覚コンテンツからテキストを抽出することができ、効率的なデータ抽出と分析を促進します。
ChatGPTはどのように画像からテキストを抽出するのか?
ChatGPTは、OpenAIのコードインタープリターという、その能力を強化するPythonベースのプラグインを使用して、画像からテキストを抽出します。GPT-4 VLM(視覚言語モデル)を搭載したChatGPTは、画像内のアルファベット文字や人間の顔などの視覚要素を認識するコンピュータビジョンの特定のタイプである、光学文字認識(OCR)技術を採用しています。このディープラーニング技術は、視覚データ(ピクセル)を機械が読み取れるテキストに変換します。
GPT-4を画像認識やテキスト抽出に活用することは、OCR技術とコンピュータビジョンモデルを組み合わせることで実現する高度なAI駆動型プロセスです。これらのモデルは、人間の視覚認識とコンピュータ処理のギャップを埋め、画像を機械が読み取れる形式に変換します。これにより、ChatGPTに新たな次元が加わり、テキストベースの標準的な入力だけでなく、コンテンツ作成における大規模言語モデル(LLM)と畳み込みニューラルネットワーク(CNN)の応用例が増えています。
画像からテキストを抽出するプロセスは次の通りです。
- 画像処理:画像は、分析に最適化するために、リサイズ、コントラストの向上、ノイズの低減などの前処理が行われます。
- テキスト検出:高度なオブジェクト検出技術により、文字や単語に似た形状やパターンを認識することで、テキストが含まれている可能性が高い画像の領域が特定されます。
- 特徴抽出:ChatGPTは、特定されたテキスト領域から、フォントスタイル、サイズ、方向などの関連する特徴を抽出し、正確なテキストの再構成を支援します。
- 文脈分析:これらの特徴は言語モデルにフィードされ、ChatGPTは言語の理解を適用して、文脈の中で抽出されたテキストを正確に解釈します。
- 後処理:最後に、後処理が適用され、出力が洗練され、エラーが修正され、精度が向上し、抽出されたテキストが正確で一貫性のあるものになるようになります。
このプロセス全体が、画像からテキストへの抽出のような複雑なタスクを処理するChatGPTのようなAI搭載ツールの能力が向上していることを示しています。
ChatGPTのビジョンモデル
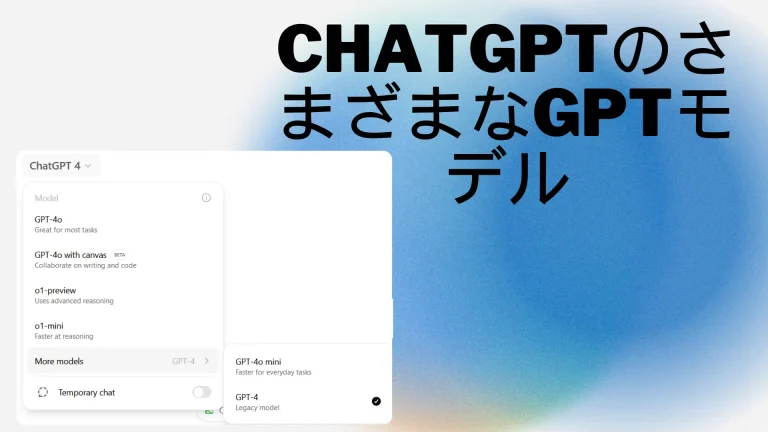
ChatGPTのビジョンモデルでは、ユーザーは画像を入力としてアップロードし、その画像に関連する質問をモデルにすることができます。プロンプトを使用することで、ユーザーは画像として提供された入力に基づいてモデルにタスクを実行させることができます。GPT-4o、GPT-4o mini、GPT-4 Turboにはビジョン機能があります。これらのモデルは、GPT-4の既存の機能に基づいて構築されており、テキストのインタラクション機能と組み合わせた視覚分析を提供します。従来、言語モデルシステムはテキストという単一の入力モダリティのみの処理に制限されていました。ビジョンモデルは、ChatGPT Plusとエンタープライズユーザーを対象に、月額20ドルで提供されています。
ビジョンモデルの機能には、以下のものが含まれます。
- GPT-4o、GPT-4o mini、GPT 4-Turboなどのビジョンモデルは、写真、スクリーンショット、文書などの視覚的なコンテンツを受け入れ、さまざまなタスクを実行できます。
- これらのモデルは、画像内のオブジェクトを識別し、その情報を提供することができます。
- ChatGPTのビジョンモデルは、グラフ、チャート、その他のデータ可視化など、視覚的な形式で提示されたデータの解釈と分析に精通しています。
- テキスト解読機能により、モデルは画像内の手書きのメモやテキストを読み取り、解釈することができます。
OCR用のChatGPTビジョンモデルにアクセスする方法は?
ChatGPTのビジョンモデルにアクセスする方法は次のとおりです。
- から直接ChatGPTのウェブサイトにアクセスします
- 最新のアップデートによると、ユーザーはChatGPTに直接アクセスできます。ただし、ビジョンモデルにアクセスするには、ユーザーはサインアップしてプラスオプションをアップグレードする必要があります。
- ChatGPT Plusにアクセスします。 ダウンすると、モデルセレクターでGPT-4モデルが表示されるようになります。 GPT-4またはGPT-4oをクリックして、ChatGPTのビジョン機能にアクセスします。
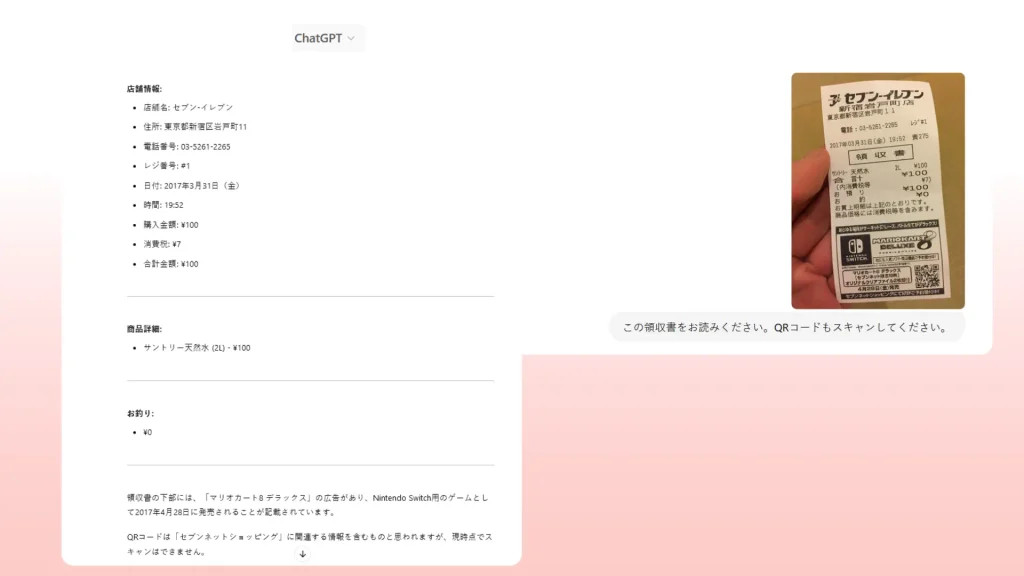
- 「クリップ」アイコンをクリックし、テキスト画像を機械可読のテキスト形式に変換します。 フォームや領収書をスキャンし、スキャンを画像ファイルとして保存することができます。
- ファイルをアップロードしたら、ChatGPTにテキストを抽出するように指示します。例えば、「この画像からテキストを抽出してください」または「このPDFテキストを編集可能なコンテンツに変換してください」と言うことができます。
- ChatGPTのビジョンモデルは、画像またはPDFを分析し、OCR技術によりテキストを検出し、編集可能な機械可読テキストとして抽出します。
- 抽出されたテキストはチャットに表示され、必要に応じて確認、コピー、編集することができます。
OCRにおけるChatGPTのユースケースと用途
ChatGPTのOCR機能は、個人ユーザーと幅広い業界の両方にとって、数多くの価値あるアプリケーションの扉を開きます。ChatGPTのOCRアプリケーションは、日常業務や顧客とのやり取りにおける効率性、正確性、アクセシビリティを向上させることで、さまざまな業界に力を与えます。以下に、主なユースケースをいくつか紹介します。
デジタルコミュニケーション
ChatGPTのOCR機能は、手書きや印刷されたコンテンツをデジタル化し、異なる言語間でも簡単にアクセスできるようにすることで、デジタルコミュニケーションを変革します。例えば、ユーザーは画像や文書からテキストを抽出して、好みの言語に翻訳することができます。これにより、グローバルなコミュニケーションが強化され、より深い理解が促進されます。
小売
小売業界では、ChatGPTのOCR機能により、ユーザーが自分のデバイスで直接クーポンやプロモーションコードをスキャンして利用できるようになり、顧客体験が効率化されます。このプロセスにより、プロモーションが簡素化され、顧客エンゲージメントが向上し、シームレスなショッピング体験を提供することで顧客満足度が向上します。
銀行業界
ChatGPTのOCRは、モバイル小切手入金や顧客情報の確認など、銀行業務の自動化に重要な役割を果たします。このテクノロジーは、金融取引の正確性とスピードを高め、機密データのセキュリティを確保しながら業務効率を改善します。
ヘルスケア
ヘルスケアの分野では、ChatGPTのOCRは患者の記録、医療報告書、治療履歴をデジタル化し、医療従事者が重要な情報に簡単にアクセスできるようにします。このテクノロジーは、データ管理の効率性を高め、患者情報へのタイムリーなアクセスを確保することで、ヘルスケアの提供を改善します。
保険業界
ChatGPTのOCRは、保険業界における保険金請求処理を自動化し、ワークフローを高速化し、手作業によるエラーを削減します。フォームや文書からのデータ抽出を自動化することで、OCRは保険金請求の決済の精度を向上させ、顧客体験を向上させます。
観光
観光業界では、ChatGPTのOCRは、ホテルや旅行プラットフォームでのパスポートスキャンによる自動チェックインを可能にし、よりスムーズな体験を実現します。この自動化により、ホスピタリティを提供する側の効率が向上し、旅行者にはより便利で手間のかからない体験が提供されます。
法律業務
法律事務所は、ChatGPTのOCRを活用して、宣誓供述書、判決、申請書などの重要な法律文書をデジタル化することができます。これにより、記録の検索性、整理、アクセシビリティが向上し、文書管理が効率化され、法律業務全体のワークフローが合理化されます。
制限事項
GPT-4 with visionは強力な機能を提供しますが、ユーザーが認識しておくべき一定の制限事項があります。例えば、このモデルはCTスキャンなどの専門的な医療画像の解釈には適しておらず、医療上のアドバイスを得るために頼るべきではありません。また、日本語や韓国語などのラテン文字以外のテキストを含む画像を処理する際には、最適なパフォーマンスが得られない場合があります。また、このモデルは小さなテキストの処理にも苦労しており、重要な詳細が切り取られないようにしながら、テキストを拡大して読みやすくすることをお勧めします。さらに、このモデルは回転または上下逆さまの画像を誤って解釈することがあり、特に色や線のスタイルにバリエーションがある場合、グラフなどの視覚要素を正確に解釈することが難しい場合があります。
空間的な推論や正確さの面では、チェスの駒の位置を特定するなど、正確な位置特定を必要とするタスクに課題が生じる可能性があり、シナリオによっては不正確な説明やキャプションが生成される場合があります。さらに、GPT-4はメタデータや元のファイル名を処理しないため、パノラマ画像や魚眼画像、元の寸法を変更したリサイズ画像にも対応できません。また、画像内の物体の数を近似値しか提供できない場合もあり、実装された安全プロトコルにより、CAPTCHAを処理できない場合もあります。 これらの制限があるにもかかわらず、ビジョンを搭載したGPT-4は、多くのタスクに対応できる多用途なツールです。
結論
結論として、ChatGPTのビジョンモデルは、画像やスキャンした文書などからのテキスト抽出を自動化する強力な機能を提供します。このテキスト認識機能は、アクセシビリティの障壁を打破し、レガシー文書や画像ベースの文書から貴重な洞察を引き出し、数多くのクリエイティブなアプリケーションへの道を開きます。
よくある質問(FAQs)
アップロードできる画像のサイズに制限はありますか?
はい、ChatGPTのビジョンモデルを使用する場合、ユーザーは1ファイルあたり最大20MBの画像をアップロードできます。
どのような種類のファイルをアップロードできますか?
ChatGPTのビジョンモデルは、PNG (.png)、JPEG (.jpegおよび.jpg)、WEBP (.webp)、アニメーションではないGIF (.gif)などの画像形式をサポートしています。
画像が不明瞭な場合はどうなりますか?
画像が曖昧または不明瞭な場合、モデルはそれを解釈しようと試みますが、結果は正確性を欠く可能性があります。一般的なガイドラインとして、画像内の情報が、その解像度(低解像度または高解像度に関わらず)において、一般の人にとって容易に識別できない場合、モデルも同様に苦労する可能性が高いでしょう。